



 管理员
管理员




保姆级的Clawdbot部署教程
第一步:装上这个狠角色先说Mac和Linux的兄弟们,找台不怕折腾的电脑(千万别用工作机),复制下面这行命令:curl -fsSL https://clawd.bot/install.sh | bash Windows用户也别走,打开PowerShe...

EmbedAI部署教程:从零开始搭建企业级私有AI系统的完整指南
【免费下载链接】EmbedAIAn app to interact privately with your documents using the power of GPT, 100% privately, no data leaks项目地址: https://gitcode.com/gh_mirrors/em/EmbedAI想要...

LobeChat零基础部署教程:5分钟搭建私人AI聊天助手
LobeChat零基础部署教程:5分钟搭建私人AI聊天助手你是否想过拥有一个完全属于自己的AI聊天助手?不是那种需要登录外部网站、数据可能被收集的在线服务,而是一个真正部署在你本地环境、数据完...

DeepSeek 本地部署详细教程,0基础轻松搞定!
前言DeepSeek 作为国产开源大模型,近期因在线服务压力过大,本地部署需求激增。本教程将结合全网优质资源,手把手教你完成从环境配置到交互界面搭建的全流程,即使是零基础用户也能轻松掌握。...

2026年,本地部署大模型需要什么配置?
先说结论:本地跑大模型,显存是最核心配置,其他硬件都是配角。9B模型量化版,8G显存可以跑,但很勉强;16G才算舒服。27B模型需要24GB显存起步,16G卡跑不动。122B模型,消费级单卡基本别想,...

如果本地要装大模型,建议哪个开源大模型?
实测12G显卡跑QWEN3.5 35B A3B Q6K速度42token/s,上下文多一些的情况下也有37token/s,如果用Q4KM,速度可以达到55token/s,上下文多一些也差不多50token/s。显卡是4070ti 12G,CPU i5-14600KF...

零成本,谷歌 Gemma 4「本地部署」保姆级教程
养龙虾终于不用花钱了。谷歌最新的开源模型 Gemma 4,原生支持 function calling。装在你自己的电脑上,接入 OpenClaw,token 成本直接归零。划重点,Gemma 4 是 Gemma 家族第一次用 Apache 2...

永久免费的OpenClaw Token,用最快的方式部署一个本地大模型
龙虾🦞OpenClaw,消耗Tokens的速度快到一眨眼钱包就空了,如何永久有效的使用免费tokens ?我们用最快的方式在自己的电脑上部署大模型。分两步:第一步:部署Ollama第二步:部署Open WebUI做完...

Qwen3.5 0.8B/2B/4B/9B 小模型本地部署指南,微调教程
Qwen快捷部署工具对于不少朋友来讲,大模型部署还是有难度的,尤其适应了国内软件那种一键式傻瓜式操作,很多要靠手搓完成的操作,实践过程中理解成本比较高。所以我给大加找了一个快捷Qwen本地...
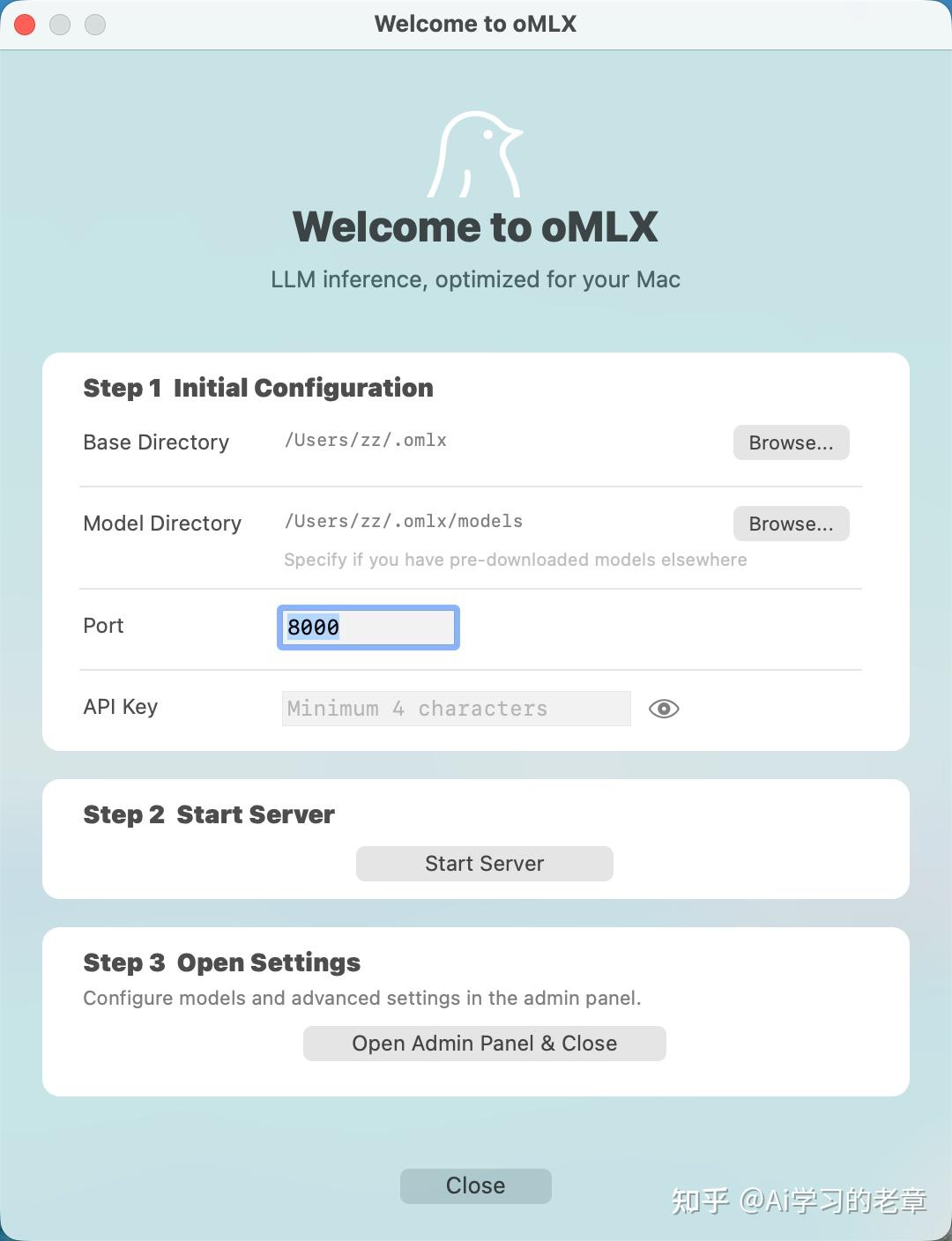
oMLX,Mac端大模型本地部署新选择,Claude-Opus-4.6 Qwen3.5-9B
oMLX 走的是 Apple Silicon + MLX 这条路,Windows 和 NVIDIA 这边的朋友,这篇先看看热闹就好前文实测 Claude-Opus-4.6 蒸馏版 Qwen3.5,9B 已能打,用 LM-Studio 本地跑,对接 Claude Code,...