



显卡是4070ti 12G,CPU i5-14600KF,内存32G 6000MT/s
使用的软件是LM Studio


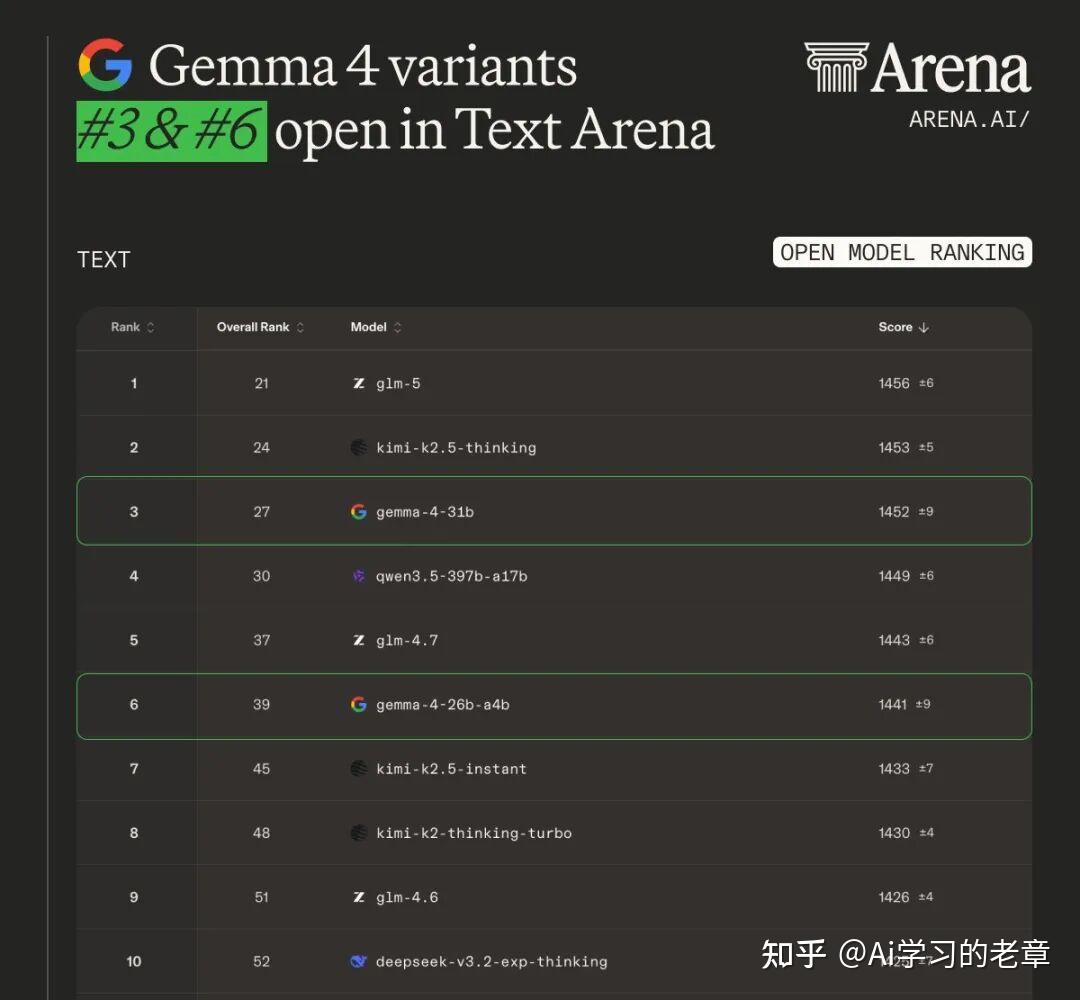
下载的是unsloth QWEN3.5 35B Q6K。


除了unsloth外下面两个也不错,看你自己选择。


加这个可以关闭思考模式
{%- set enable_thinking = false %}


如果上下文长度在4000token左右,速度可以跑到42-43token/s,拉长到20K的上下文长度,速度会降到37-39token/s,但哪怕是37这个速度也足够快了,而且这是Q6K,可能更多的人会选择Q4KM的精度,上下文多一点的情况下也能超过50token/s。


我主要用的是QWEN3.5 9B、35B、27B这三个模型。
目前使用来看,QWEN3.5 35B的优势是速度快,但各方面能力都逊色于27B,大多数时候比9B强。最大的缺点是处理超长文本、大段内容总结方面还不如9B,远不如27B。
QWEN3.5 9B我用下来感觉略弱于QWEN3.5 35B,速度也快不到哪里去,Q6K速度56token/s,Q4KM速度70token/s,那我还不如用35B。但9B在超长上下文的事后速度还是很快,也比35B靠谱。
QWEN3.5 27B非常猛,比QWEN3.5 35B强,能和QWEN3.5 122B-A10B互有胜负,但我这个12G显卡跑27B Q4KM只有3.6token/s的速度,几乎不能用。16G显卡跑27B估计也挺吃力的,我猜只能跑Q3量化,只有24G显卡才能稳稳的跑27B,又或者起码24G的苹果笔记本才能勉强跑跑27B。
具体使用的话看你的需求。肯定优先用27B,但如果27B你带不动,速度连10token/s都达不到,那还是别勉强了,在35B和9B里面做选择吧。
35B在大多数时候都比9B强,但是35B在长上下文,譬如长文总结、大段内容分析理解回答这方面不如9B(长文本逻辑性、叙事连贯性)。还有就是指令服从稳定性比较差,不如9B。





暂无评论内容