



oMLX 走的是 Apple Silicon + MLX 这条路,Windows 和 NVIDIA 这边的朋友,这篇先看看热闹就好
前文实测 Claude-Opus-4.6 蒸馏版 Qwen3.5,9B 已能打,用 LM-Studio 本地跑,对接 Claude Code,评论区好几个兄弟推荐测试 oMLX:
- 博主有时间可以研究一下oMLX这个替代 LM Studio,据说比 lm 快很多倍。
- 听说 omlx 比 lm studio 更好用些,占用内存更小,有没有尝试部署一下?
- 有大佬做成适合 omlx 跑的 fp8 量化版了,大概 10G,可以试试。同样机器配置,换用了 oMLX 跑 qwen3.5 9b MLX Q4 版,利落了些,15token 左右吧。虽然回复慢,但还能用。而 ollama 跑就卡顿的很。
花半天玩了一下,先看大家最关心的测试情况:
- oMLX 有很多亮点,UI、菜单栏、管理后台仪表板,Chat 页面都很漂亮,底层有 SSD KV 缓存、设置热缓存、支持 MCP、一键对接各种 AI Coding Agent,OpenAI/Anthropic 兼容接口、针对 Claude Code 优化等
- 单请求生成速度约 20 token/s,峰值显存/统一内存占用约 5.7GB
- 无法硬跑 Qwen3.5-27B-Claude-4.6-Opus-Distilled-MLX-4bit,LM Studio 可以强跑,但只能加载,执行任务直接彻底卡死
安装、配置、使用教程
安装后直接进入 Perference,自定义模型位置,端口号
模型位置后面我把他改到了外接移动硬盘
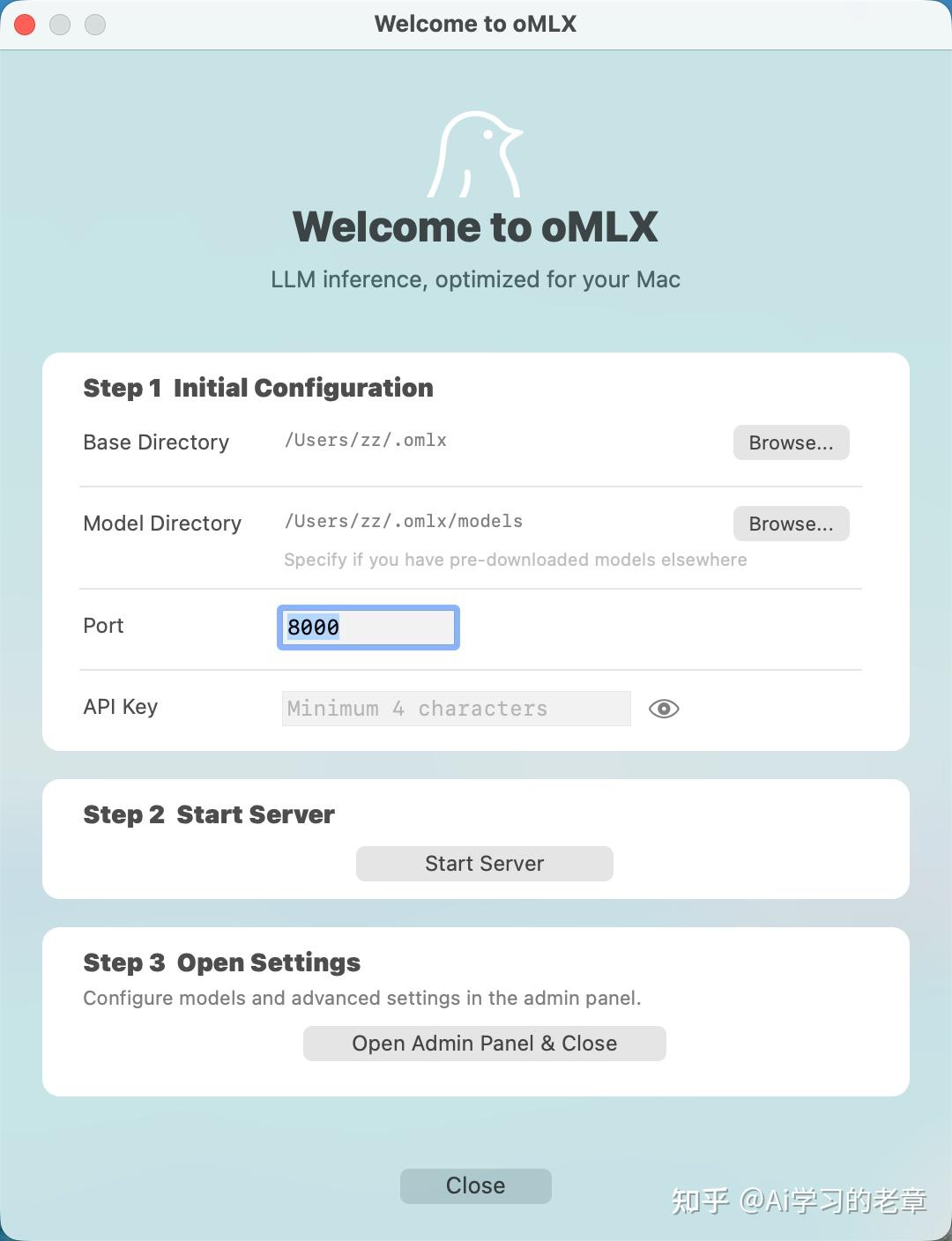
菜单栏确实方便,一键启停 server、进入管理后台,进入聊天界面

先要进入模型 tab 然后点下载器

下面的浏览模型可以直接看能否支持当前主机

下载速度极慢,后来我换成了 modelcope

感觉也有 bug,直接从上面下载,他会默认下载整个项目下的不同精度模型,而我只需要 Q4

27B 我也下了
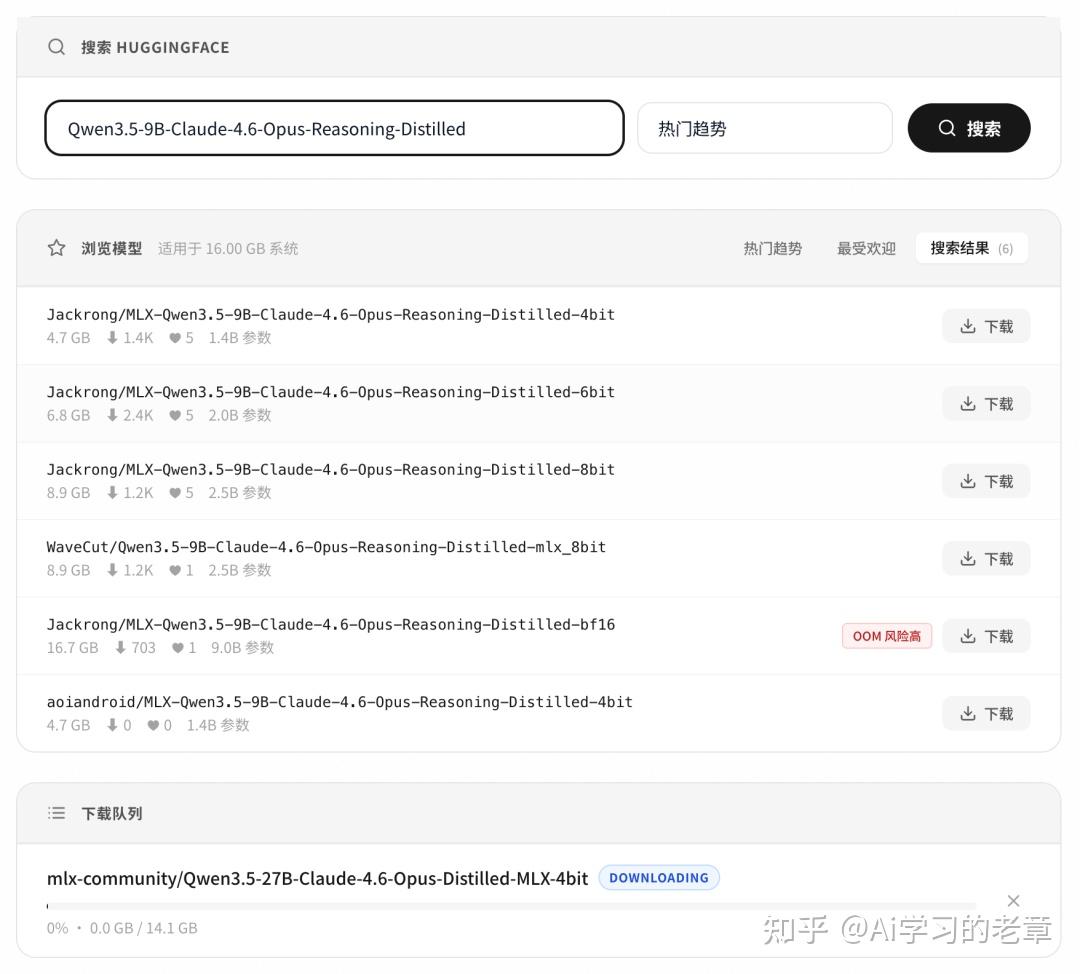
没有选择 Jackrong 原版,主要是被 mlx-community 这句话吸引了

但是 27B 最低使得 24 GB 及以上统一内存的 Mac 都能运行该模型,且还有足够空间容纳大型上下文窗口,推荐是 32GB
官方测试数据:
| Metric | Result |
|---|---|
| Model load time | 2.4 seconds |
| Prompt ingestion | 86.5 tokens/sec |
| Generation speed | 15.7 tokens/sec |
| Peak RAM usage | 15.6 GB |
| Bit-rate | 4.501 bits/weight |
| Final size | 14 GB (3 shards) |
下载过程中进入设置页

资源管理这里可以控制内存占用情况,

下载完毕,可以选择在设置 – 模型设置中启动,刚开始居然没找到哪里加载

聊天页面,很清爽

仪表盘会记录模型运行情况

现在往下也能把启动的模型一见接入到 Codex、OpenCode、OpenClaw

它还可以做基准测试

32K 单请求测试,电脑已经有点卡了,TTFT 高的离谱,TPS 只有 11
| 测试 | TTFT (ms) | TPOT (ms/tok) | pp TPS | tg TPS | 端到端延迟 | 吞吐量 | 峰值内存 |
|---|---|---|---|---|---|---|---|
| pp32768/tg128 | 174812.5 | 85.62 | 187.4 tok/s | 11.8 tok/s | 185.686s | 177.2 tok/s | 9.06 GB |
单请求 + 批处理能力没敢开高,tg TPS 20.2 tok/s。输入拉长到 4096 token 后 TTFT 从 4.8s 变成 18.8s,tg TPS 还在 19.8 tok/s,几乎没掉,Peak Mem 从 5.66 GB 到 6.40 GB
并发到 2-4 路时总吞吐提升明显,但 8 路已经接近平台上限,延迟代价很大。

依旧测试阅读理解+SVG 代码生成 + 审美
感觉不稳了,需要抽卡

重新尝试可以识别到四次,svg 写的很丑

让其优化之后,它的脑回路让我想笑,它直接设计了模拟人物动作,完全偏离了主题

27B 无法跑起来
改了 N 多配置都不行,有高手可以出出主意
我要换 32G 的 Mac 了

但是 LM Studio 就可以用 option 按键强跑,只是无法执行任务,机器卡死

其他再说说
看了官方文档,再说几个 oMLX 的亮点,可是我都没尝试
1. 连续批处理
它基于 mlx-lm 的 BatchGenerator 做并发处理,首页给了一组非常直观的 benchmark,机器是 M3 Ultra 512GB,模型是 Qwen3.5-122B-A10B-4bit:
- 单请求、8k 上下文时,Prompt 处理速度能到 941 tok/s
- Token 生成速度大约 54.0 tok/s
- 在
8x连续批处理下,总吞吐能到 190.2 tok/s - 对应 3.36 倍吞吐提升
- 内存占用峰值 73 GB
另一组我很关注的数据是 Qwen3-Coder-Next-8bit:
- 8k 上下文时,Prompt 处理速度 2009 tok/s
8x批处理总吞吐 243.3 tok/s- 加速比来到 4.14 倍
- 内存占用峰值 85GB
2. Claude Code 优化
README 里有一句:
支持在 Claude Code 中使用较小上下文模型的上下文缩放。通过缩放上报的 Token 数量,让自动压缩在合适的时机触发,同时提供 SSE keep-alive 防止长时间预填充导致的读取超时。
官方给出的方向主要有两个:
- 通过上下文缩放,让较小上下文模型在 Claude Code 里更容易触发合适的自动压缩时机
- 通过 SSE keep-alive,降低长时间 prefill 时读超时的风险
它本身还支持:
- OpenAI 兼容接口:
http://localhost:8000/v1 - Anthropic 兼容接口:
POST /v1/messages - 工具调用
- MCP 集成
3. 多模型服务
它在同一服务里支持:
- 文本 LLM
- VLM
- OCR 模型
- Embedding
- Reranker





暂无评论内容