

 管理员
管理员




AI大消息!五部门联合发布!
4月10日,国家网信办、国家发展改革委、工业和信息化部、公安部、市场监管总局联合公布《人工智能拟人化互动服务管理暂行办法》(以下简称《办法》),自2026年7月15日起施行。国家网信办有关负...

MiniMax海螺AI教程全解
MiniMax海螺AI是一款由上海稀宇科技有限公司(MiniMax)开发的多功能AI助手,基于自研的多模态大语言模型,旨在提升个人和团队的效率。它支持智能搜索、语音交互、实时笔记、长文总结、创意辅助...

DeepSeek保姆级教程(超详细)
精心收集了DeepSeek保姆级使用教程,让你快速上手,从零到精通,毫无难度。1、零基础使用DeepSeek高效提问技巧2、教大家如何使用Deepseek-AI进行超级降维知识输出V1.0版3、DeepSeek-搞钱教程(0...

本地部署 DeepSeek R1 越狱版:无限制、无审查、全自由!
提示先看:你有没有想过,拥有一个不联网也能跑的大模型,没有任何限制、不审查你说的话,甚至道德框架都不强加?现在,它真的来了——DeepSeek R1 越狱版(deepseek-r1-abliterated),已上线...
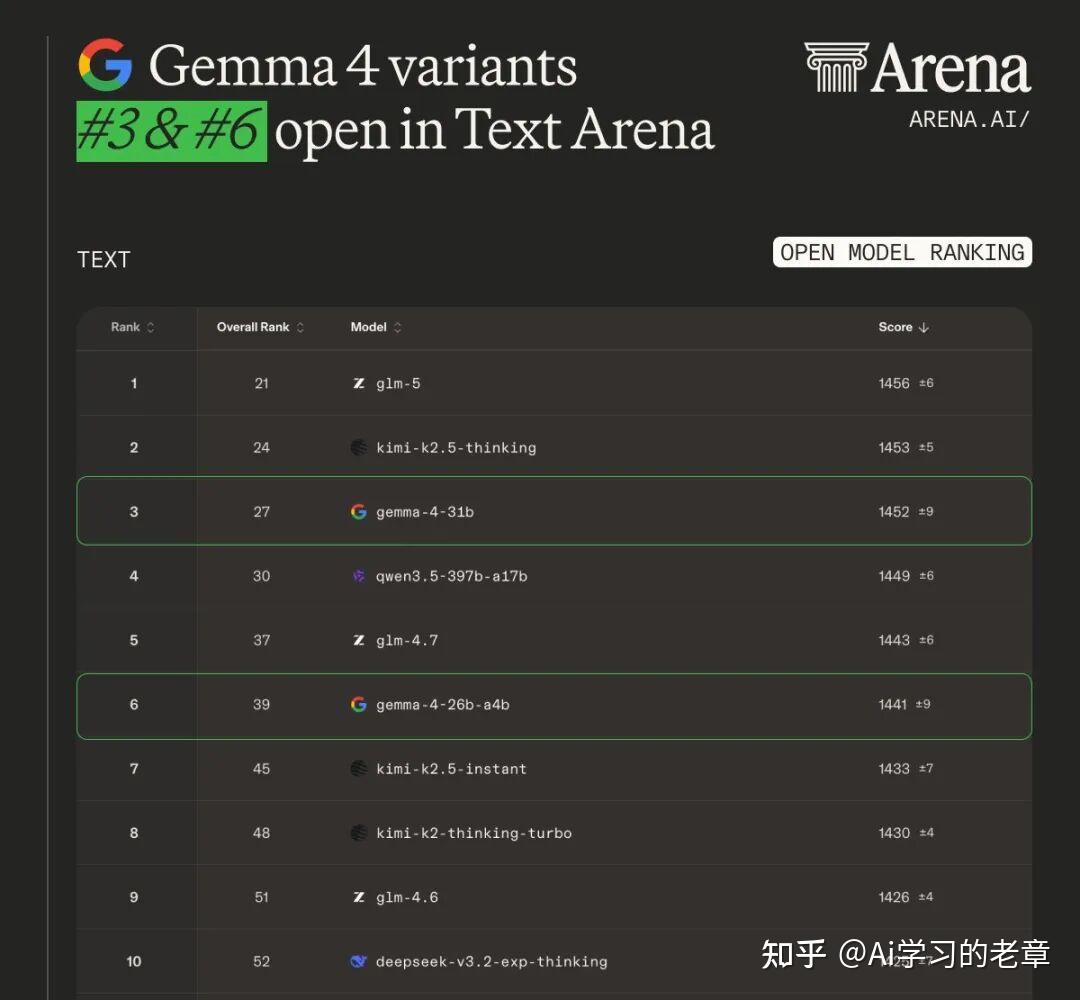
Gemma 4 全系列本地部署指南:Ollama / llama.cpp / MLX / vLLM,附 TurboQuant 显存优化
一句话总结:这是目前参数效率最高的开源模型家族,十分之一参数量,媲美旗舰模型四款模型,各有定位Gemma 4 一口气发布了四个尺寸的模型:来逐个看看它们的定位:31B Dense —— 全密集架构...
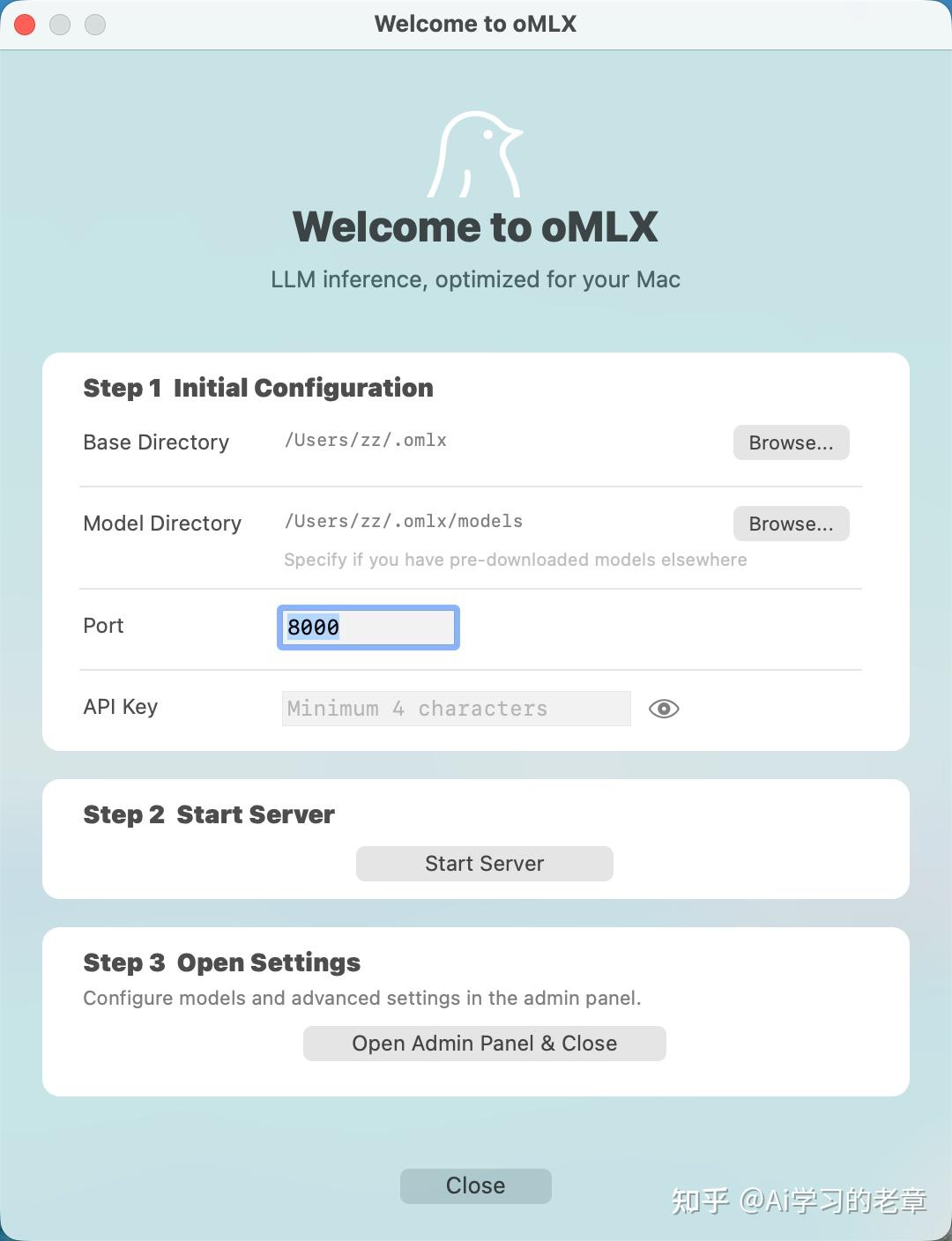
oMLX,Mac端大模型本地部署新选择,Claude-Opus-4.6 Qwen3.5-9B
oMLX 走的是 Apple Silicon + MLX 这条路,Windows 和 NVIDIA 这边的朋友,这篇先看看热闹就好前文实测 Claude-Opus-4.6 蒸馏版 Qwen3.5,9B 已能打,用 LM-Studio 本地跑,对接 Claude Code,...

Qwen3.5 0.8B/2B/4B/9B 小模型本地部署指南,微调教程
Qwen快捷部署工具对于不少朋友来讲,大模型部署还是有难度的,尤其适应了国内软件那种一键式傻瓜式操作,很多要靠手搓完成的操作,实践过程中理解成本比较高。所以我给大加找了一个快捷Qwen本地...

永久免费的OpenClaw Token,用最快的方式部署一个本地大模型
龙虾🦞OpenClaw,消耗Tokens的速度快到一眨眼钱包就空了,如何永久有效的使用免费tokens ?我们用最快的方式在自己的电脑上部署大模型。分两步:第一步:部署Ollama第二步:部署Open WebUI做完...

零成本,谷歌 Gemma 4「本地部署」保姆级教程
养龙虾终于不用花钱了。谷歌最新的开源模型 Gemma 4,原生支持 function calling。装在你自己的电脑上,接入 OpenClaw,token 成本直接归零。划重点,Gemma 4 是 Gemma 家族第一次用 Apache 2...

如果本地要装大模型,建议哪个开源大模型?
实测12G显卡跑QWEN3.5 35B A3B Q6K速度42token/s,上下文多一些的情况下也有37token/s,如果用Q4KM,速度可以达到55token/s,上下文多一些也差不多50token/s。显卡是4070ti 12G,CPU i5-14600KF...